1、前言
因为工作需要,领导让我爬取下国家行政区划代码。本来觉得是件很简单的事,因为看结构,这个还是挺简单的,但是实现起来却发现不是那么回事。
我们先看下页面长什么样子:国家统计局区划代码
页面展示的是省级区划代码,点进去依次是市、县(区)、乡镇、街道区划代码,一共5级。(正常的数据都是5级,其中中山市、东莞市、儋州市这3个特殊,只有4级,需要特殊处理)。
页面结构蛮简单的,就是个级联数据,我这里就不贴图了。
2、爬虫工具
我选用的node+cherrio+puppeteer,puppeteer是一个基于chrome的无界面浏览器。具体使用方法,我这里就不详细介绍了,刚兴趣的可以点这里,教程。
3.思路
刚开始爬取数据,我的想法很简单。
数据是一级级的,我爬取的时候也一级级爬就行(也就是深度遍历)。
我先爬取省页面,然后遍历这些省,获取下一级页面的链接(市页面链接)。然后我再依次打开这些链接,获取到市的数据和下下级页面的链接(县页面链接),我再打开下下级页面链接获取数据和下下下级页面链接,以此类推。
这样等获取完了,我就得到了一个大的json数据,我再把数据存成一个json或者excle。就可以完美交差了。
估计很多小伙伴跟我思路一样,但是这个思路是行不通的。原因有以下两点:
1.程序可调试性太差,数据涉及4层循环,而且每个循环里都是异步操作。有一个地方出错了,整个程序就无法进行。很多时候,你还不知道那个地方出错了。很多时候,运行了半天了,一个错误,导致前面的努力都会白费。
2.数据量很大,我本来以为数据量没多少,实际数据量是几十M。用记事本都打不开,也许你们的电脑可以吧,可怜我的破电脑是打不开的。
综上两点,我们得转变思路。
于是我改用广度遍历的方法。我先爬取省级数据存起来,再爬取市级数据存起来,再爬取县区数据,以此类推。
4.行动
有了思路,我们开始行动,要存储数据,可以选择文件或者数据库,我实际选择了mongo数据库,这里为了演示方便,我改用文件存储。
上面废话了很多,我这里就不废话了,直接贴程序。 文末有完整代码
4.1 打开浏览器
要爬取数据,首先我们要创建一个浏览器,然后用程序控制这个浏览器打开我们想要的页面,从而得到页面内容。
创建浏览器的代码比较复杂,是因为要规避网站的一些反爬虫机制。
1 | const puppeteer = require('puppeteer'); |
关闭浏览器
1 | async function pageClose(browser){ |
4.2 辅助函数
1.引入node模块
1 | const path = require('path') |
2.获取浏览器
定义了2个全局变量,browser和page
1 | let [browser, page] = [null, null] |
3.获取页面内容
1 | async function getPageContent(page, url) { |
4.获取下一级页面的链接
1 | function getRelativeBaseUrl(url) { |
5.根据页面内容获取数据
这里用到了cherrio,具体用法点这里,cherrio教程
1 | function getHrefsByContent(url, content) { |
6.将数据存储到文件
1 | function createDataFile(fileName,dataStr,basePath='.') { |
4.3 获取省数据
获取省份数据的地址是这个,2021年统计用区划代码和城乡划分代码
1 | // 获取省份的地址 http://www.stats.gov.cn/tjsj/tjbz/tjyqhdmhcxhfdm/2021/index.html |
4.4 存储省级数据
1 | async function saveProData() { |
5.获取省数据
保存省数据的函数是saveProData ,我们把它暴露出来
1 | saveProData() |
我代码是保存在temp.js文件里。shell端执行node temp.js,就会执行saveProData函数。
得到文件如下
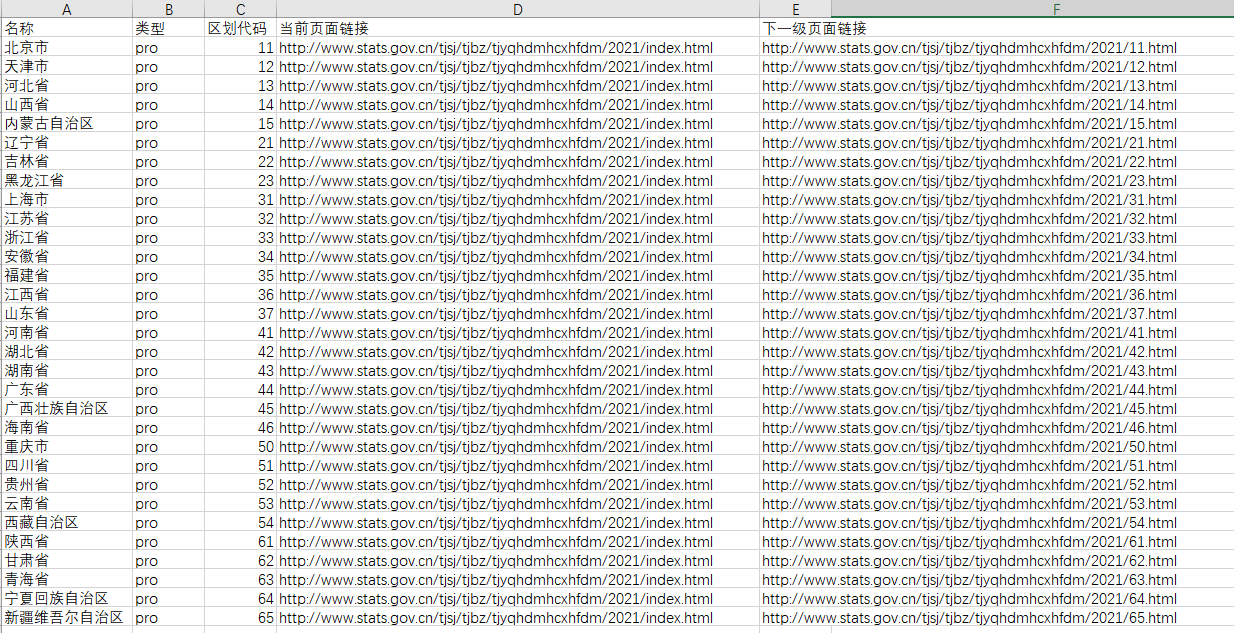
ok,我们就获取到省级数据了。
6.获取市数据
通过上面的操作,我们获取到了省数据和各省下一级的页面地址(nextUrl),也就是市级页面的地址。 遍历省数据,依次打开市级页面地址,就可以获取到市数据和下一级(县区)页面地址。依次类推,我们就可以获取到所有我们想要的数据。
代码我就不贴了,授人以鱼不如授人以渔。我想我已经把渔的方法说的很清楚了。感兴趣的小伙伴可以自己实现。
7.爬取的结果
本人写这个爬虫,花了3天左右的时间,不想要这么麻烦的小伙伴,可以直接联系我。我可以提供json或excle格式的数据。
前提是我不是免费的哦,爬取的方法免费说了,数据多少要收点辛苦钱。中年人有孩子有家,没办法。但也不贵,只需要一杯咖啡钱(20元)。需要的可以联系我,微信:guo330504。或者扫二维码
如果有爬虫、前端相关的外包也可以找我

本人爬取完整的数据截图如下:
省列表:
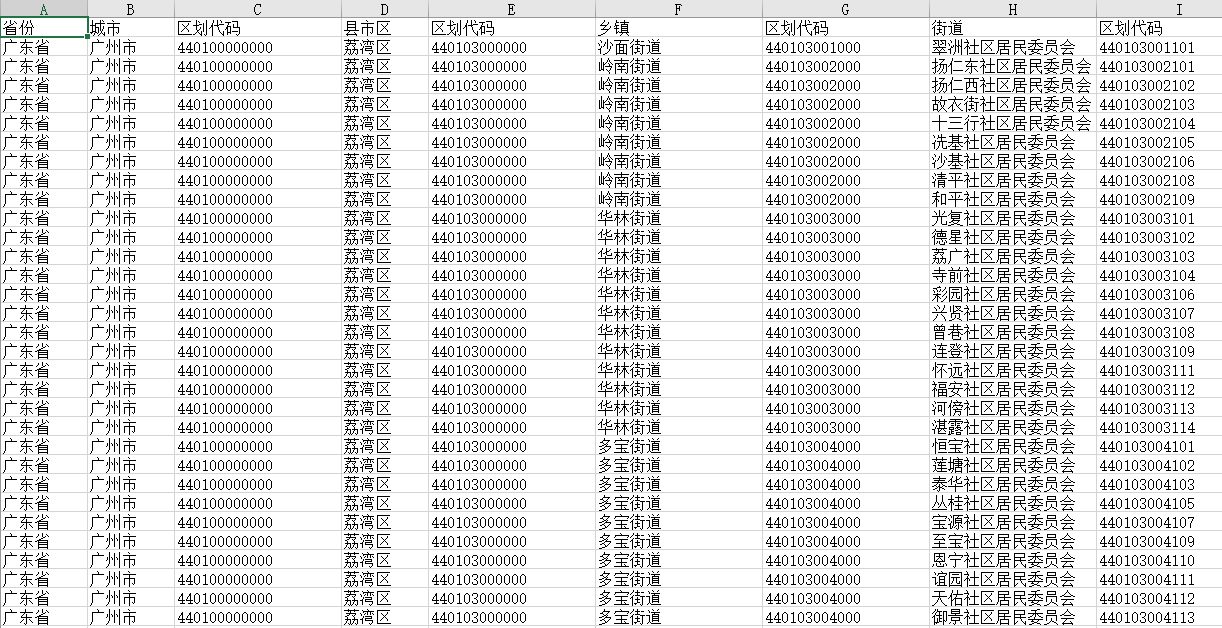
以广东为例,广东数据如下:
广州市数据如下:
7.完成代码
爬取省数据完整代码如下:
1 | const path = require('path') |

